[Spring Batch 1] 스프링 배치 빠르게 시작해보기 (with DEVOCEAN)
DEVOCEAN에서 스프링 배치 스터디를 모집하였고 운좋게? 나도 참여할 기회가 주어져서 열심히 스터디를 해보려고 한다. 스터디를 진행하며 KIDO님의 연재글을 기반으로 실습한 내용을 github에 올리고 공부하고 정리한 내용을 블로그에 포스팅할 것이다.
스프링 배치 스터디의 첫번째 주제는 ‘SpringBatch 빠르게 시작하기’ 이다.
1. Spring Batch 초기화 및 실행
1-1. 프로젝트 초기화
먼저 스프링배치 프로젝트를 생성해야 한다. 기도님의 포스팅에서는 https://start.spring.io 에서 프로젝트를 생성하고 있다.
간단한 스프링 프로젝트 초기화는 IntelliJ IDE에서도 가능하기 때문에 나는 IDE로 프로젝트를 생성하였다.

다음과 같이 프로젝트를 설정하고 dependency를 선택하는 부분에서 spring-batch를 선택한 후에 프로젝트를 생성하였다.

build.gradle에 위의 spring-batch 의존성이 잘 설정되어 있는 것을 확인할 수 있다.
1-2. 프로젝트 실행
터미널로 gradle :bootRun 명령어를 실행해보자.

어플리케이션 실행 및 빌드 실패하였다. 실패 로그를 보니 DataSource ‘url’ 속성이 지정되지 않았다는 내용이 나온다. 스프링배치는 기본적으로 배치와 관련된 메타데이터를 관리하기 위해 Database에 자동으로 스키마를 생성하기 때문에 DB 연동이 필요하다.
실패 로그에 친절하게 embedded database를 사용할 것을 추천하고 있다. 해당 스터디에서는 간단하게 H2 Database를 활용할 것이다.
2. H2 Database 연동

build.gradle에 H2 database 의존성을 추가하자.

application.yml에 DB 접근 및 설정을 위한 환경변수들도 세팅하였다.
3. Spring Batch Application 실행
gradle :bootRun 명령어를 다시 실행해보자.

Spring 어플리케이션이 잘 실행되고 있는 것 같다..!


정상적으로 어플리케이션이 실행되고 빌드도 성공하는 것을 확인할 수 있다.
(어플리케이션이 실행되고 바로 종료된다. 스프링배치 어플리케이션에서는 실행할 배치 작업이 없으면 바로 종료되는 듯 하다..)
4. Spring Batch MetaData란?
위에서 언급하였던 메타데이터에 대해 좀 더 알아보자.
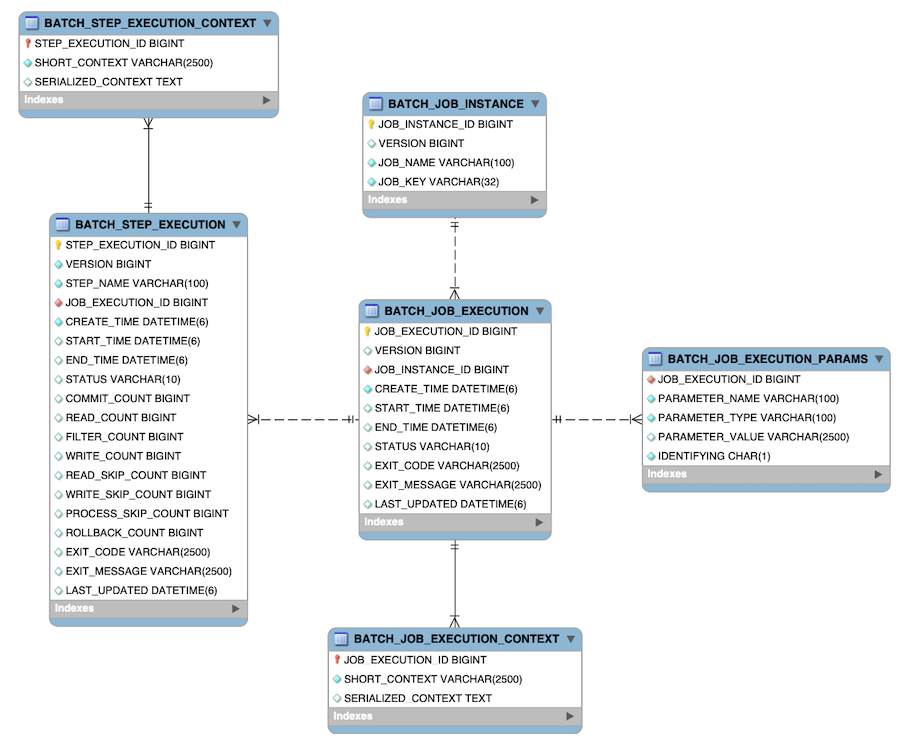
공식문서 참고: https://docs.spring.io/spring-batch/reference/schema-appendix.html
Spring Batch의 메타데이터 스키마는 배치 작업의 실행 기록을 추적하고, 재시작 시 상태를 관리하는 데 사용된다. 스키마는 주로 다음과 같은 주요 테이블들로 구성된다.
BATCH_JOB_INSTANCE: 배치 작업의 인스턴스 정보를 저장하는 테이블로, 각 작업의 고유 식별자를 관리한다.BATCH_JOB_EXECUTION: 배치 작업의 실행 정보를 저장하며, 작업이 언제 시작되고 종료되었는지 등의 정보를 기록한다.BATCH_STEP_EXECUTION: 각 step의 실행 기록을 저장하며, step이 성공적으로 완료되었는지, 오류가 발생했는지를 추적한다.BATCH_JOB_EXECUTION_PARAMS: 배치 작업 실행 시 사용된 파라미터를 저장한다. 이를 통해 동일한 배치 작업이 다른 파라미터로 여러 번 실행될 수 있다.BATCH_JOB_EXECUTION_CONTEXT: 배치 작업 실행 중 사용된 컨텍스트 정보를 저장하며, 작업 재시작 시 필요한 상태를 유지하기 위해 사용된다.
관련 스키마 DDL을 확인해보고 싶다면, 위의 참고로 남긴 공식문서에 접속하여 확인할 수 있다. 이 메타데이터 테이블들은 Spring Batch가 작업을 효과적으로 관리할 수 있게 도와주고, 작업이 실패했을 때 중단된 지점에서 다시 시작할 수 있도록 하는 중요한 역할을 해준다. 즉, 배치 작업이 진행됨에 있어서 안정성과 신뢰성을 확보해주는 스프링 배치의 핵심적인 요소라고 볼 수 있는 것이다.
또한 배치 작업 이벤트가 실행될 때마다 자동으로 기록되고, Spring-Batch가 이를 관리해주기 때문에 개발자는 비즈니스 로직에 좀 더 집중할 수 있다.
메타데이터에 대해서는 이론적으로 완벽하게 알고 넘어가기 보다는, 추후 실습을 통해 데이터가 어떻게 쌓이고 관리되는지 확인하면서 이해하는 것이 좋을 것 같다고 판단되어 여기까지만 정리하고 넘어가야겠다.
참고 : [SpringBatch 연재 01] SpringBatch 빠르게 시작하기